GPU Networks Overview
Multi-Tenant GPU-to-GPU Network Provisioning and Management
Modern AI workloads demand a dedicated, high-performance network fabric that connects GPUs within and across compute nodes, separate from general-purpose infrastructure networks.
The NVIDIA Spectrum-X Compute East-West (E-W) network provides a purpose-built Ethernet fabric optimized for GPU-to-GPU communication at cloud scale.
From version 25.06, zCompute GPU Network (GPU-Net) exposes this fabric as a first-class, self-service resource. Tenants can provision and manage GPU networks through zCompute’s standard interfaces. Tenants can have multiple GPU networks, and can allocate these networks across multiple projects that provide project isolation and tenant isolation.
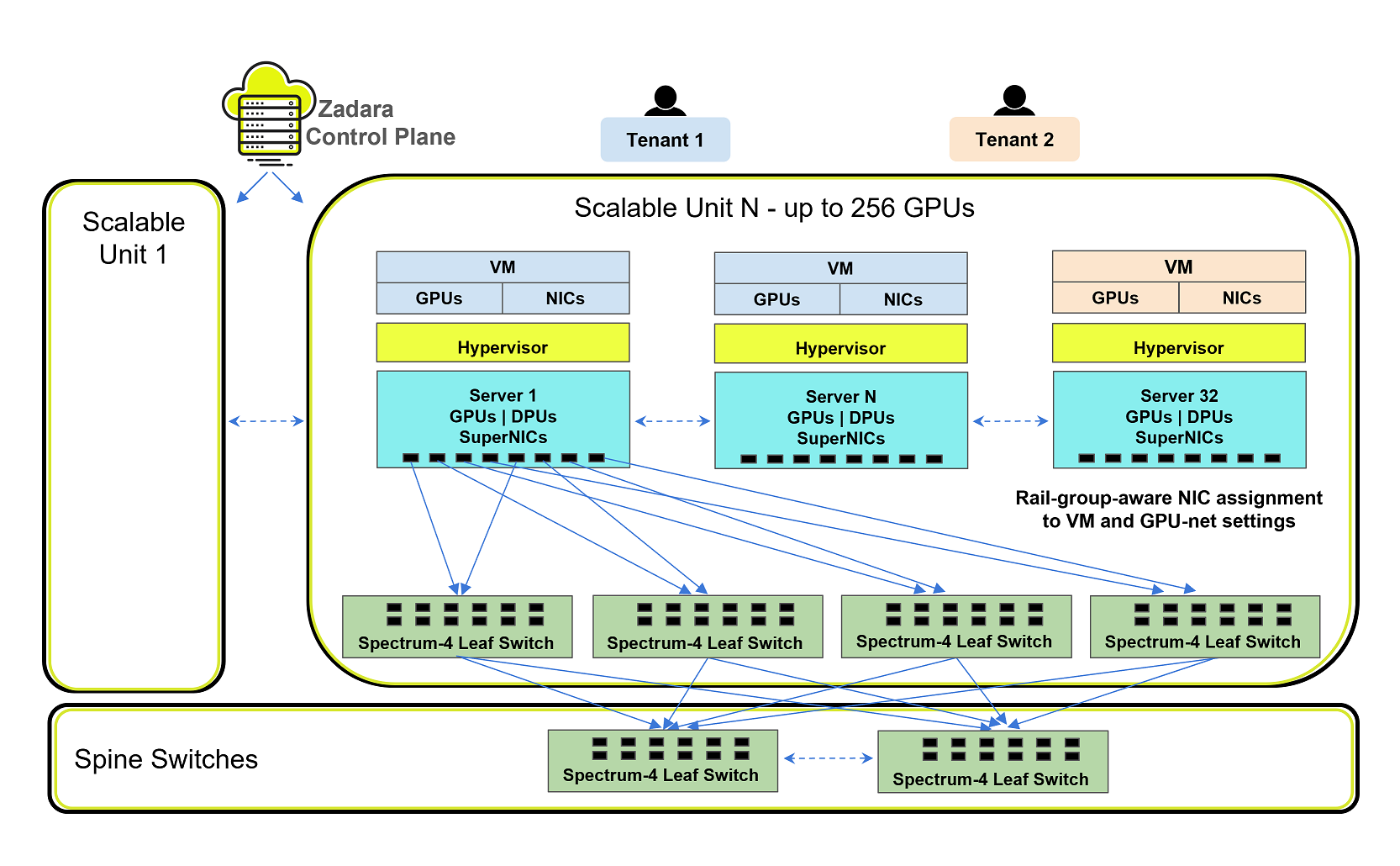
Background: The NVIDIA Compute East-West Network (Spectrum-X)
What is the East-West Network?
In a GPU AI cloud, network traffic flows in two distinct directions:
North-South (N-S):
Traffic between compute nodes and the outside world: user access, storage, management, and orchestration. This is a standard Ethernet fabric shared across the data center.
East-West (E-W):
Traffic between GPUs, across nodes, within the AI compute fabric. This is the Spectrum-X network: a dedicated, rail-optimized, high-bandwidth Ethernet fabric built exclusively to serve GPU collective communication workloads (NCCL, RDMA, etc.).
The East-West network is entirely separate from the North-South fabric in both cabling and function. It carries no management or storage traffic: it exists solely for GPU-to-GPU communication.
Spectrum-X Architecture
NVIDIA Spectrum-X is the networking platform underlying the E-W fabric. It combines:
NVIDIA Spectrum-4 (SN5600) Ethernet switches:
64-port, 800 Gbps per port, delivering up to 128 x 400 Gbps of line-rate switching capacity per switch.
NVIDIA BlueField-3 B3140H SuperNICs:
Dual-port 400 GbE SmartNICs installed in each HGX compute node, providing the host-side GPU network interface and enabling hardware-accelerated network virtualization (VXLAN overlays, RoCE, adaptive routing, congestion control).
Cumulus Linux / NVUE:
The network operating system on the Spectrum-4 switches, providing an API-first, schema-driven configuration model used for automated fabric bring-up and multi-tenancy configuration.
NVIDIA NetQ:
Real-time network telemetry and validation tooling for the E-W fabric.
Rail-Optimized Topology
The E-W fabric uses a rail-optimized topology: the defining structural choice of NVIDIA’s GPU network architecture. In an HGX server with 8 GPUs, each GPU is connected via a dedicated BlueField-3 SuperNIC to a specific rail of leaf switches. This means:
GPU traffic between nodes within the same rail never traverses a spine switch, minimizing hop count and latency.
Each HGX node connects to the leaf switches with two uplinks per rail, at speeds of 400 Gb/s or faster.
The fabric scales from a single Scalable Unit (SU) of 32 HGX servers (256 GPUs) up to tens of thousands of GPUs using a two-tier (leaf + spine) or three-tier (leaf + spine + super-spine) topology, without requiring re-cabling.
The basic fabric building block is the Scalable Unit (SU):
32 HGX nodes with 4 rail groups
Each rail group served by its own set of leaf switches
Multiple SUs connect to shared spine switches to form a cluster
Multiple clusters form PODs
PODs connect via super-spines for the largest deployments
Scale |
GPUs |
SUs |
Topology |
|---|---|---|---|
Single SU |
256 |
1 |
2-tier (leaf only) |
4 SUs |
1,024 |
4 |
2-tier (leaf + spine) |
16 SUs |
4,096 |
16 |
2-tier (leaf + spine) |
Key Network Technologies
The Spectrum-X E-W fabric is built around several technologies that work together to deliver near-lossless, high-throughput GPU communication:
RoCE (RDMA over Converged Ethernet):
GPU collective communication libraries (NCCL) use RDMA to transfer data directly between GPU memory across the network, bypassing the CPU. This achieves maximum bandwidth and minimum latency.
Adaptive Routing:
The Spectrum-4 switches dynamically select the least-congested path on a per-packet basis, distributing GPU collective traffic evenly across all available links rather than relying on static ECMP hashing. This is critical for all-reduce and other collective patterns.
Spectrum-X Congestion Control (CC):
A closed-loop congestion control mechanism that adjusts transmission rates proactively to prevent buffer buildup, maintaining low latency under heavy GPU workloads.
VXLAN Overlays (BGP-EVPN):
The underlay is a pure layer-3 routed network (BGP). Multi-tenancy is implemented using VXLAN overlays with BGP-EVPN control plane, where each tenant gets its own VRF (Virtual Routing and Forwarding instance) with an associated VNI (VXLAN Network Identifier). Tenant traffic is fully isolated at the network layer.
W-ECMP (Weighted Equal-Cost Multi-Path):
Load-balancing across multiple equal-cost paths in the fabric underlay, complementing adaptive routing for traffic distribution.
Multi-Tenancy in the E-W Fabric
Multi-tenancy on the Spectrum-X E-W network is achieved through a combination of:
VRF-based isolation on the switches:
Each tenant is assigned a dedicated VRF on every leaf switch, with a unique VNI and Route Distinguisher (RD). Tenant routes are never leaked between VRFs, ensuring complete L3 isolation.
VXLAN encapsulation:
Tenant GPU traffic is encapsulated in VXLAN as it traverses the fabric, logically separating it from other tenants’ traffic even on shared physical links.
BlueField-3 SuperNIC enforcement:
The SuperNIC on each host enforces tenant network membership at the endpoint, ensuring that a tenant’s GPU workload only communicates within its assigned overlay network.
Per-tenant interface assignment:
Leaf switch ports connected to HGX nodes are assigned to specific tenant VRFs based on the provisioned configuration. A tenant occupying specific GPUs on a node has precisely those GPU-facing switch ports mapped into its VRF.
The Reference Configuration Playbook (RCP), NVIDIA’s Ansible-based automation framework for Spectrum-X, handles the translation of high-level tenant provisioning intent into the detailed switch and SuperNIC configuration across the entire fabric.
zCompute GPU-Net Feature
What Is GPU-Net?
GPU-Net is the zCompute capability that automates the provisioning, lifecycle management, and isolation of East-West GPU networks for cloud tenants. It bridges the zCompute control plane with the underlying NVIDIA Spectrum-X E-W fabric, giving tenants self-service access to high-performance GPU-to-GPU networking as a managed cloud resource.
When a tenant deploys GPU instances on zCompute, GPU-Net ensures that those GPUs are connected through a logically isolated, high-performance E-W network: independent of the tenant’s regular VM networking and invisible to other tenants.
Why GPU-Net?
Without a managed GPU network layer, cloud operators face a difficult choice. Sharing the fabric across tenants isn’t an option.
The choice is between one of the following options:
Choosing a semi-manual allocation process characterized by rigidity, inefficiency, and a lack of self-service.
A fully-automated solution such as GPU-Net provided by zCompute.
GPU-Net solves this by:
Automating per-tenant E-W network provisioning:
Eliminating manual fabric reconfiguration for every tenant GPU allocation.
Enforcing strict network isolation:
Tenants can only reach the GPUs within their own GPU-Net, regardless of physical co-location on the same nodes or switches.
Enabling multi-tenant GPU clusters:
Multiple independent tenants can share the same physical Spectrum-X infrastructure safely and simultaneously.
Abstracting Spectrum-X complexity:
Tenants interact with GPU-Net as a cloud networking primitive; the underlying VXLAN/VRF/BGP-EVPN configuration is invisible to them.
Key Capabilities
Capability |
Description |
|---|---|
Self-service provisioning |
Tenants create and manage GPU networks through the zCompute API/UI, without operator intervention. |
Multi-tenant isolation |
Each GPU-Net is a dedicated overlay network (VRF + VNI); traffic is fully isolated from other tenants. |
Scalable fabric integration |
GPU-Net maps tenant networks onto the physical Spectrum-X E-W fabric across any supported topology (2-tier or 3-tier). |
RoCE & RDMA support |
The provisioned network is RDMA-capable, enabling GPU collectives (NCCL) to run at full bandwidth. |
Lifecycle management |
GPU-Net tracks the full lifecycle: create, attach, detach, and delete, of tenant GPU networks and their GPU instance memberships. |
Network visibility |
Tenants have visibility into their GPU-Net topology and health through the zCompute portal. |
Relationship to Other zCompute Networks
GPU-Net is distinct from, and complements, regular zCompute tenant networking:
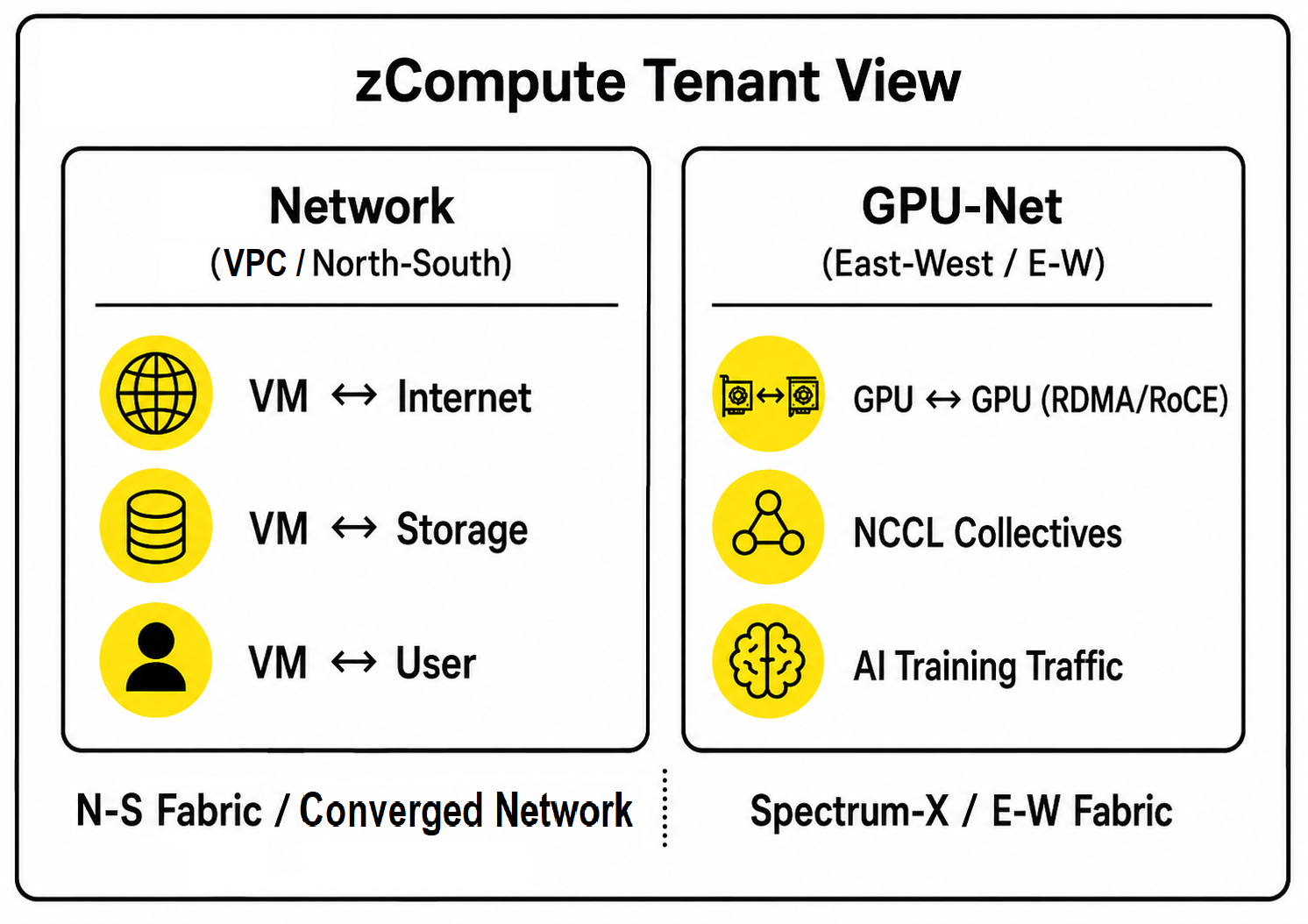
A GPU instance is attached to both networks simultaneously: its regular vNIC connects to VPC subnets, that are implemented on the North-South network. Its GPU NIC (BlueField-3 SuperNIC) connects to the GPU-Net for high-performance GPU-to-GPU communication.
Summary
The NVIDIA Spectrum-X East-West network is the industry-leading GPU fabric for AI cloud infrastructure: a rail-optimized, RoCE-capable Ethernet network with hardware-enforced multi-tenancy via VXLAN/BGP-EVPN overlays. It is physically and logically separate from all other data center networks, dedicated exclusively to the demands of GPU collective communication.
zCompute GPU-Net makes this fabric a managed, multi-tenant cloud resource. It automates the provisioning and isolation of per-tenant GPU networks on top of the Spectrum-X infrastructure, enabling cloud operators to efficiently and securely serve multiple independent AI tenants on shared GPU hardware, all through the standard zCompute control plane.